This is a quick introduction to one-way analysis of variance (ANOVA), taken from Moore and McCabe, Introduction to the Practice of Statistics, Freeman, New York, 1993. Let's begin with a clear statement of what ANOVA is used for:
Given "scores" from samples from several population groups, ANOVA is used to decide whether the differences in the samples' average scores are large enough to conclude that the groups' average scores are unequal. The null hypothesis is that all the groups have equal averages, and that any differences in the sample averages are due to chance. Then ANOVA computes a variable F on the basis of this hypothesis, and the larger the value of F, the more unlikely it is, and hence the more likely that at least one of the populations has an average different from the others. If F is not large enough, the conclusion is that all the populations have equal averages.
Moore and McCabe's discussion runs to some 50 pages; I have tried to summarize and supplement it in a mere 2 pages. Since the supplement involves some technical algebra, I have presented it in a separate document: Discussion in .pdf format. It includes some additional assumptions for ANOVA to be a valid test and describes Moore and McCabe's comments about the fulfilling of those assumptions.
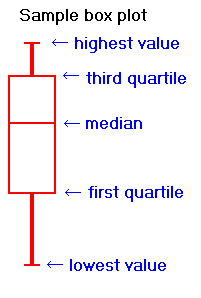
| To describe what the variable F in ANOVA measures, we nearly copy a diagram from Moore and McCabe; but first, since it uses boxplots, a form of diagram not discussed in our text, we provide a sample: | |
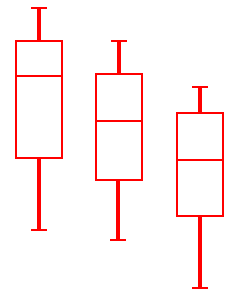 |
Now if the group samples were distributed as shown in the box plots to the left, with large spreads about their centers, then small differences between the sample averages would be less noticeable, and less significant, than if the samples were distributed as shown on the right, with exactly the same group sample averages (or at least the same medians) but small spreads within samples. | 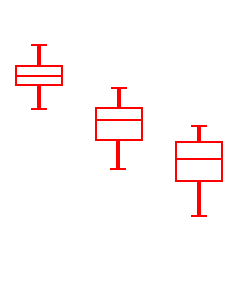 |
Thus, in order to see whether differences in sample averages from different groups are significant (i.e., if they indicate that the population groups from which the samples were drawn really have different averages), our computations must include measures of the spreads within the group samples. I.e., in deciding whether differences in sample averages are significant, we must also measure variation within the samples, of the data values from their respective sample averages, as well as measuring the spread of the sample averages from the grand average of all the data values. These spreads are related in formulas to yield a measure (the F mentioned above) of the spread of the different averages relative to the spreads within the samples. Here are the formulas; see the discussion linked above for more information:
Having computed the value of F, we can consult a table for the F-distribution to find the probability (p-value) of getting a value of F at least that large, given the two degrees of freedom (DFE and DFG) determined from the numbers of columns and entries in the table of data.
The formulas just described are obviously hard to follow, so let us "apply" them to the two sets of three box plots pictured earlier:
|
(Look again at the two sets of box plots) | |
|
Moore and McCabe's main example
is an analysis of the table of data to the right. The caption
reads as follows:
A study of reading comprehension in children compared three methods of instruction. As is common in such studies, several pretest variables were measured before any instruction was given. One purpose of the pretest was to see if the three groups of children were similar in their comprehension skills. One of the pretest variables was an "intruded sentences" measure, which measures one type of reading comprehension skill. The data for the 22 subjects in each group are given [to the right]. The three methods of instruction are called basal, DRTA and strategies. We use Basal, DRTA, and Strat as values for the categorical variable indicating which method each student received. The point to note here is that the subjects are divided into three groups according to the method of instruction they will receive, but they haven't yet received any special instruction. Indeed, the point of the test is to see whether the abilities of the test groups are essentially equal before the instruction begins. The average of each column appears in red at the bottom. Obviously the averages in the three samples differ; the question is whether they differ significantly enough to make the test of reading comprehension methods worthless. Theoretical nitpick |
|
But of course these formulas are evaluated, no longer by hand or even by calculator, but by computer. Indeed, the computer programs not only find the value of F but also find the associated p-value. Here is a screen shot from the Excel spreadsheet program, the result of using its built-in ANOVA Single Factor function on the data above. This function is available in the Tools menu under Data Analysis. (If you do not have Data Analysis in your Tools menu, see the first Excel help page linked to the course's index page.) It shows most of the values mentioned earlier and finally gives the value of F, about 3.14, that would have been large enough (given the two degrees of freedom) to conclude statistical significance (at the 5% level) of the differences between the group averages. Also, rather than the "error" vs. "groups" terminology, it uses the clearer "within groups" vs. "between groups".
